


The Right Tool For The Job?
There are so many ways to do name-screening in an AML/KYC context. Which one is right for you?
OFAC tells you that they use the SOUNDEX and Jaro-Winkler name-matching algorithms, and that there is no need to spend your money on specialized (and expensive) commercial products to do the job. But they also tell you that the search results they produce for the names that you submit to their SLSA tool are not an adequate substitute for your own due diligence (whatever that is).
So what would count as an adequate effort at clearing someone’s name, if OFAC’s own search tool can’t get the job done? How do you know what algorithm(s), product(s) and/or processing architecture(s) will get you to the Caesar’s-wife level of required blamelessness with the dreaded regulatory agencies? I’d like to suggest that you cannot hope to answer this question until you have developed at least a basic appreciation for the nature of the data that you will be attempting to match together.
First, let’s take a look at the kinds of (personal) names found in a recent (March, 2015) download of the OFAC SDN list. This pie-chart shows what happens when the OFAC person-names are sorted into seven major groups, based on what I would term the “name-models” that each name follows. I’ll explain what I mean by that term in just a moment, but let’s focus for now on the fact, obvious perhaps to many, that most OFAC names are largely drawn from a fairly small number of cultural/linguistic contexts.
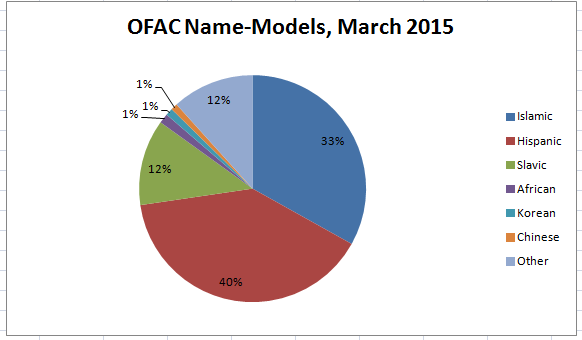
Proportion of Names Associated with 7 Name-Models in OFAC SDN Data for March 2015
Name Models for Not-Very-Model Citizens
While it is true that many of the variations that can keep one name from matching another name in an automated screening system are random in nature (typos, truncations, …), it is equally true that many forms of variation in the spelling of personal names are directly and predictably related to the “name-model” in which that name was created, and within which it was intended to operate on behalf of its bearer. Put a bit more concretely, this means that Hispanic/Latino names will vary in certain characteristic ways, as will Islamic/Arabic names, Chinese names, Korean names and the like.
Each of these cultural/linguistic groups has a certain distinctive way of creating, using and representing personal names. This, then, is generally what I mean by the term ‘name model,’ in the context of OFAC name-screening.
You don’t need to be a “quant jock” or a big-data guru to see at a glance that the OFAC SDN list is heavily tilted towards particular two name-models: Hispanic/Latino and Islamic/Arabic. And you also don’t need to be a tenured political scientist to guess why those two groups would predominate in the U.S. Government’s efforts to choke off financial support for certain designated people and organizations around the world.
In many, if not most, AML/KYC name-screening operations, the OFAC SDN names form a small portion of the names comprised within the system. Usually, there is a much more compendious and diverse set of PEP names, and there are also, of course, the customer names themselves. Each of these two datasets is likely to have its own characteristic count and distribution of name-models.
Developing a basic understanding, quantitative and qualitative, of the names that will be in circulation within your name-screening operation is, as I see it, the ineluctable first step in assessing the effectiveness of the automated mechanisms used to perform that operation. This is what I call “Know Your Data.”
Coming Soon: KYD In Action
In forthcoming posts, I will work through at least the two predominant name-models in the OFAC data, as shown above, and I will exemplify the kinds of predictable, culture-based patterns of spelling variation associated with each. Then, we can see how well OFAC’s own tools hold up, and you might possibly end up with some very uncomfortable questions for your own name-screening operation to answer.
And, we might even get another visit from our pal, the Thrifty Fisherman…
